예제
Github 예제
계속 업데이트 예정.
GitHub - chordpli/monitoring-example
Contribute to chordpli/monitoring-example development by creating an account on GitHub.
github.com
애플리케이션 관측성
애플리케이션의 출력에 기반하여 애플리케이션의 상태를 설명하고 이해할 수 있는 소프트웨어 시스템 특성 중 하나
관측 기법
- 에러와 로그 캡처
- 커스텀 지표를 이용한 코드 측정
- 분산된 애플리케이션 추적
코드와 커스텀 지표 조사
일반적인 지표 범주
- 리소스 사용 지표 : 메모리, 디스크, 네트워크, CPU 사용량 등
- 모든 인프라스트럭처는 리소스 제한이 있으므로 항상 관찰해야 한다.
- 리소스 사용량에 따라 비용을 지불해야하는 클라우드 인프라스트럭처에서 실행되는 코드에서는 특히 중요하다.
- 부하 지표: 커넥션 수, 주어진 시간 단위 동안 발생하는 리퀘스트 수 등
- 오버로드된 서비스는 일반적으로 성능이 점점 낮아지다가 크리티컬한 부하 시점을 지나면 갑자기 사용할 수 없게 된다.
- 낮은 부하 영역 또한 인프라스트럭처의 규모를 조정해서 운영 비용을 낮출 수 있는 지점이다.
- 성능 지표: 요청 또는 태스크 처리 시간
- 성능을 지속적으로 관찰하면, 애플리케이션에 새로운 변화가 추가되었을 때 발생하는 성능 하락을 발견할 수 있다.
- 비즈니스 지표: 주어진 시간 단위 동안의 회원 가입 수, 판매된 아이템 수 등
- 테스팅 프로세스에서 발견하지 못한 기능 저하 발견, 애플리케이션 인터페이스의 의심스러운 변경 등을 평가할 수 있다.
지표 모니터링 시스템이 채택하는 대표적인 아키텍처
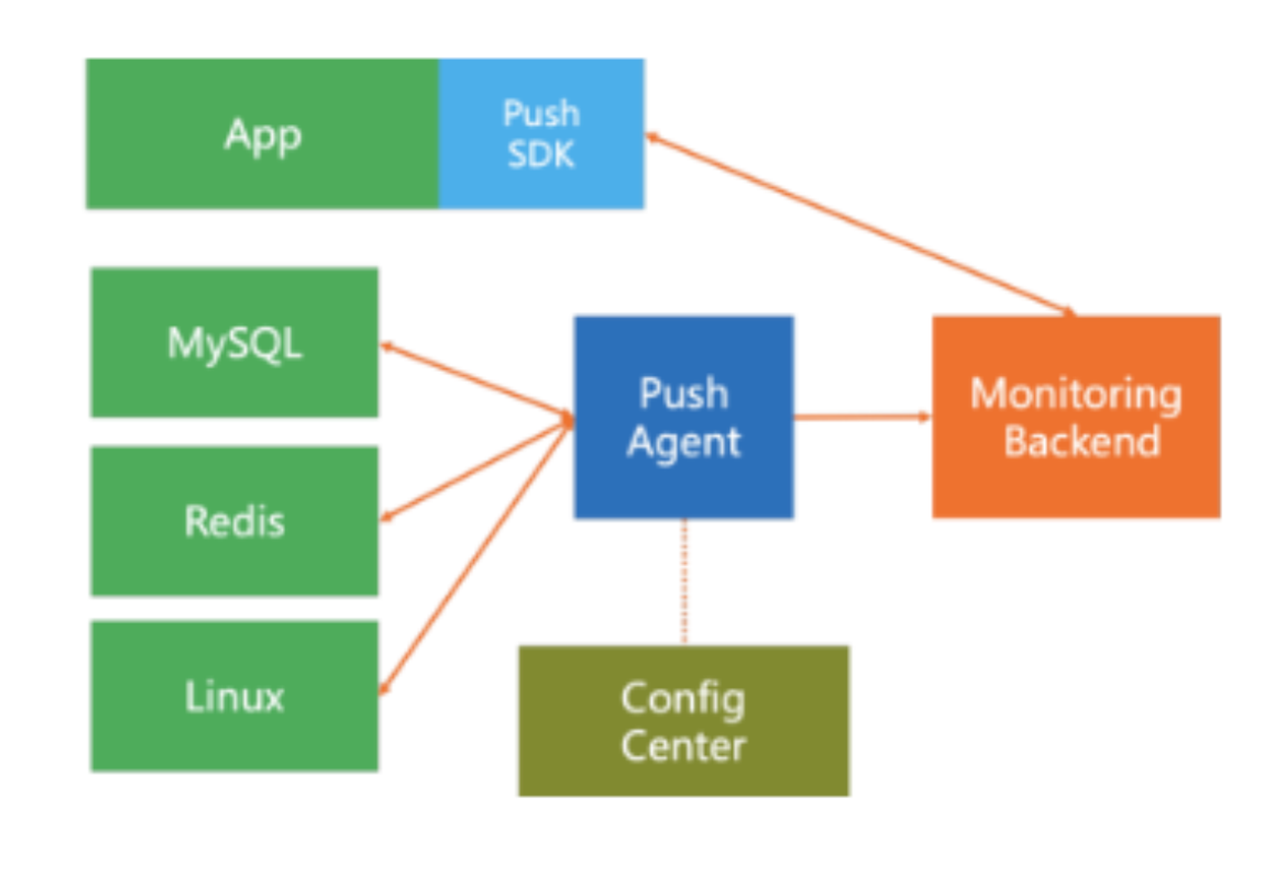
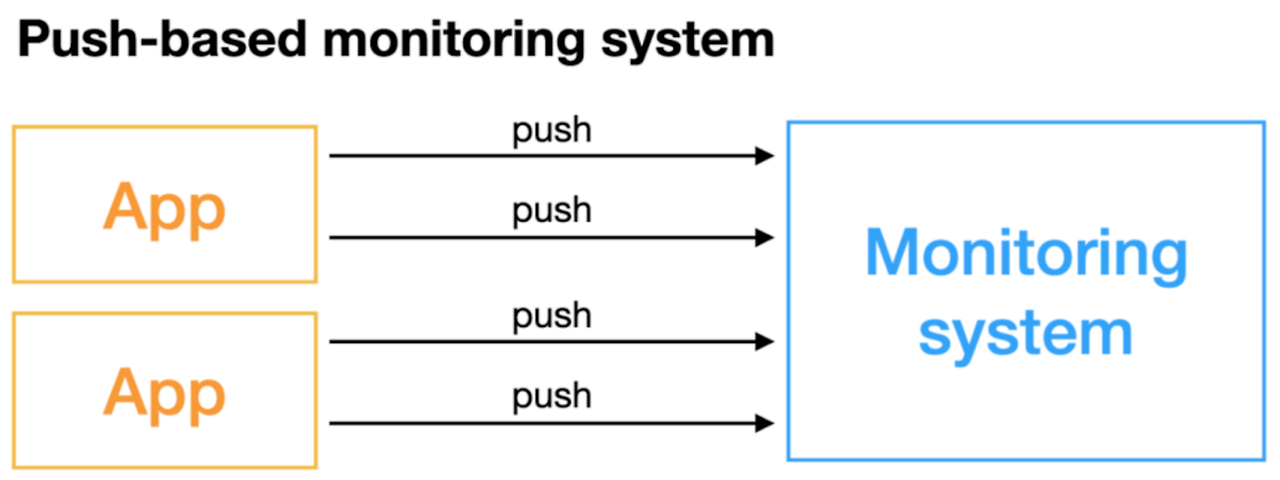
- 푸시 아키텍처: 애플리케이션이 데이터를 시스템이 밀어 넣는다.
- 원격 지표 서버 또는 로컬 지표 데몬이 다른 서버의 상위 레벨 데몬으로 지표를 보낸다. 환경 설정은 일반적으로 분산되어 있다.
- 각 서비스들은 목적지 데몬 또는 서버의 위치를 알아야한다.
- 모니터링되는 다양한 오브젝트의 메트릭 데이터를 가져와 서버에 푸시할 수 있도록 지원한다
- 대표적으로 Telegraf, InmusionDB 등의 솔루션이 존재한다.
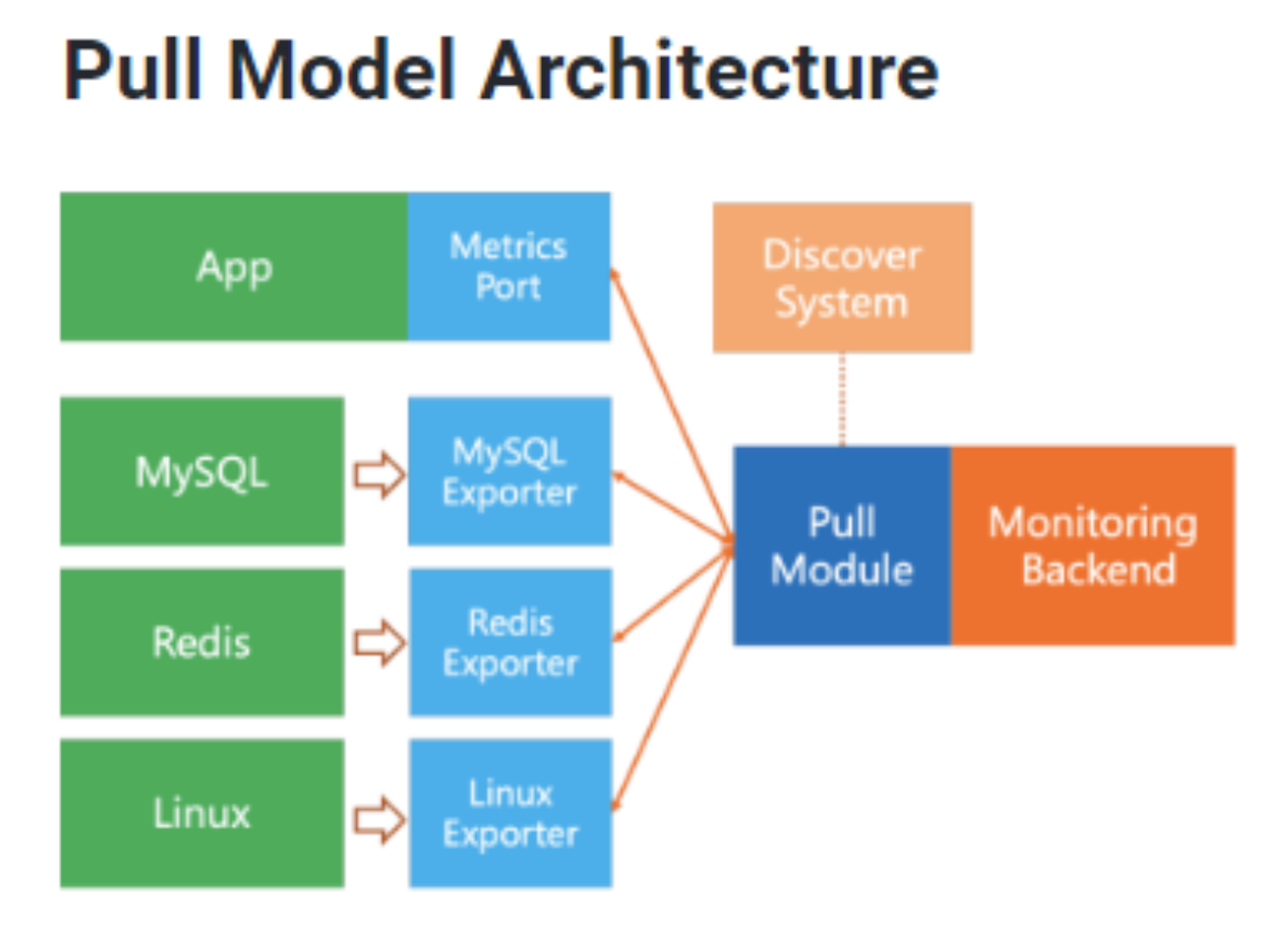
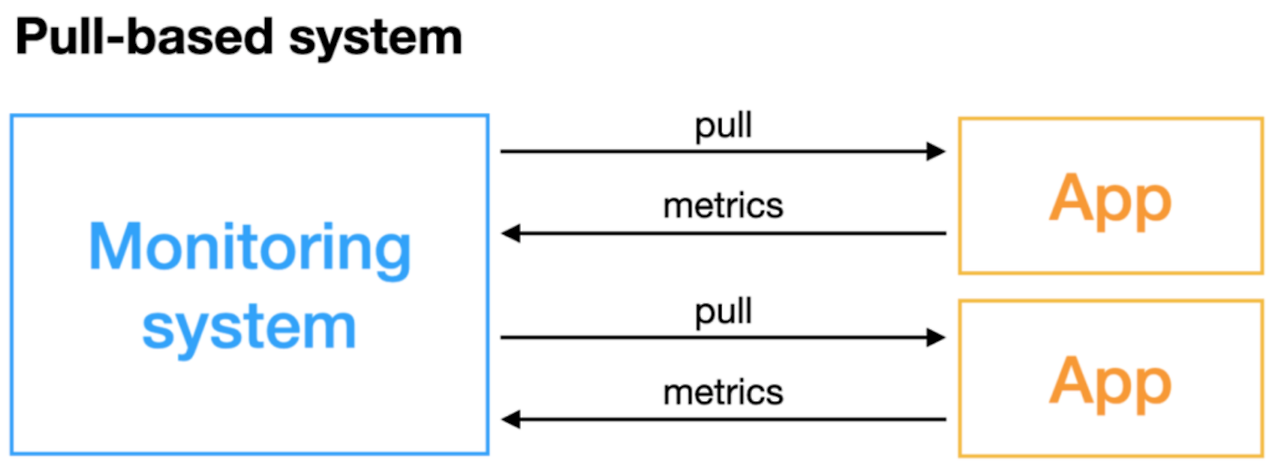
- 풀 아키텍처: 애플리케이션이 지표를 엔드포인트에 노출하고, 지표 데몬 또는 서버가 알려진 서비스로부터 해당 정보를 끌어당긴다.
- 환경 설정은 중앙화되거나, 반-분산화될 수 있다.
- Pull module은 remote end에서 데이터를 pull 하기 위한 공통 프로토콜을 사용한다.
- 대표적으로 프로메테우스 솔루션이 존재한다.
OPEN TELEMETRY + L.G.T.M
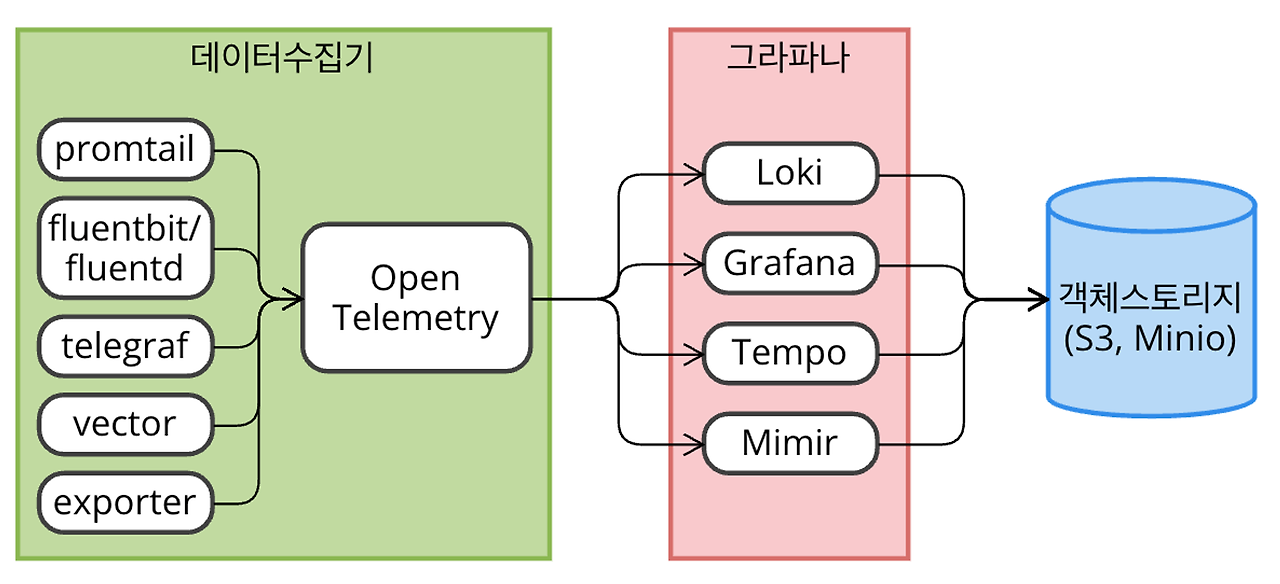
- L, Loki: 로그 관리
- G, Grafana: 대시보드
- T, Tempo: 추적 관리
- M, Mimir: 메트릭 관리
OPEN TELEMETRY
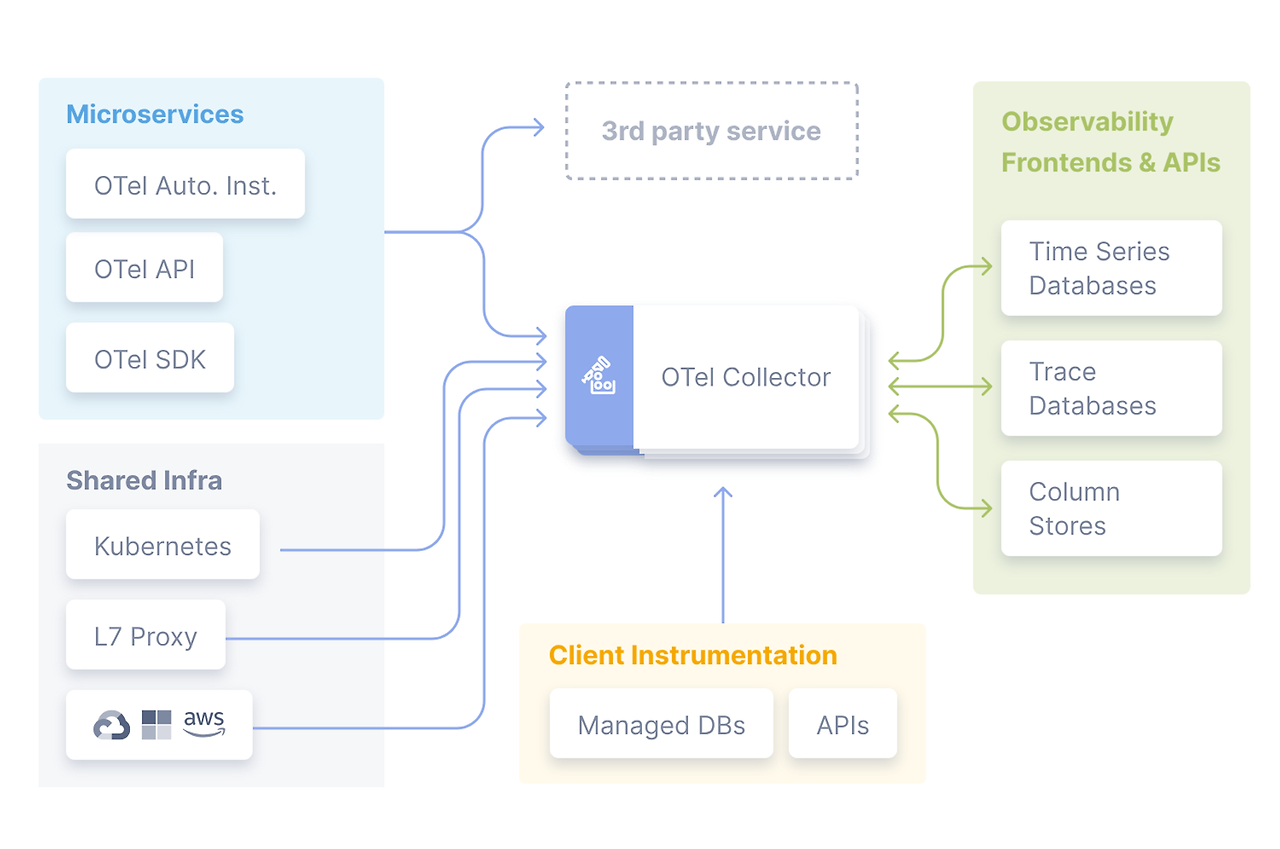
- Open telemetry는 트레이싱, 메트릭, 로그와 같은 원격 분석 데이터를 계측, 생성, 수집, 내보내기를 위한 벤더 중립적인 오픈소스 Observability 프레임워크입니다.
- 다양한 소스에서 데이터가 수집된 후, 여러 유형의 데이터베이스에 저장되고 분석되는 과정.
GRAFANA
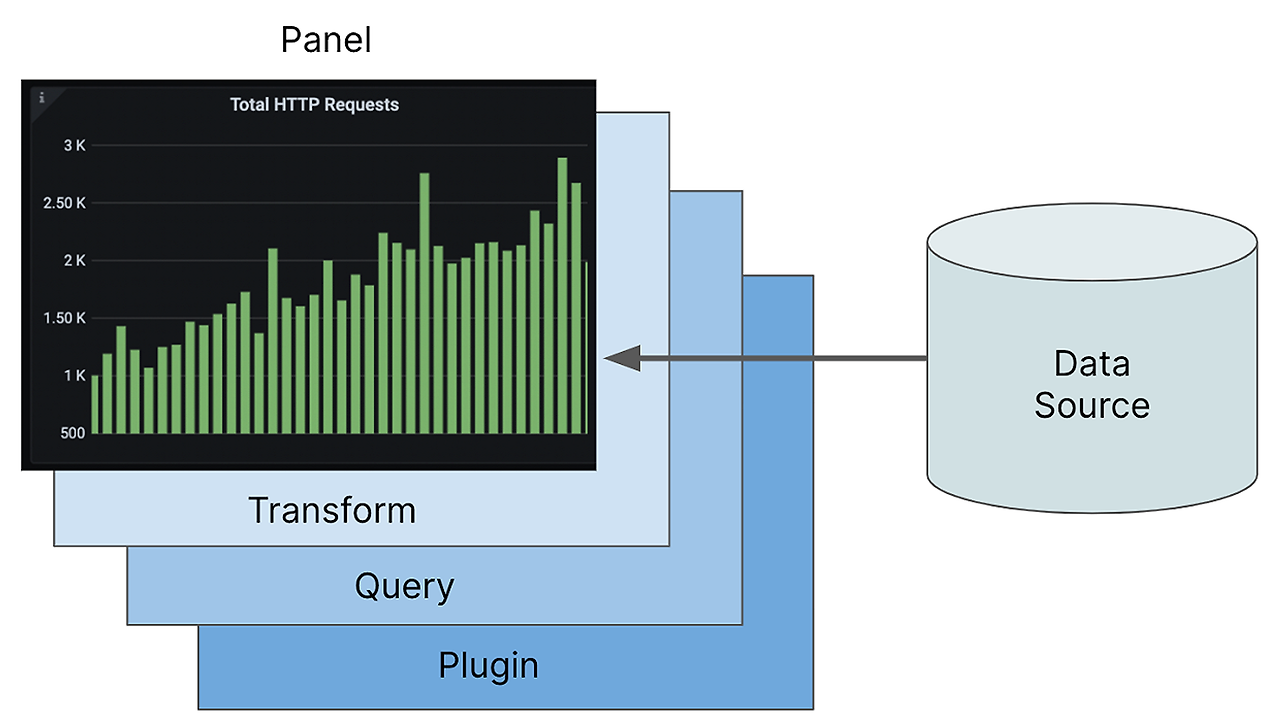
Grafana는 시각화 및 분석 소프트웨어를 제공하는 오픈 소스입니다.
메트릭, 로그 및 쿼리를 추적하며 시각화, 알림 및 탐색을 할 수 있습니다.
그라파나와 데이터독의 차이점
- 데이터독의 경우 데이터를 직접 저장하지만, 그라파나는 외부 데이터 소스를 정의하고 해당 데이터 소스에 쿼리를 통해 데이터를 동적으로 수집하여 시각화한다.
- 데이터독을 사용할 경우 메트릭 데이터를 일정 주기로 가져오기 때문에 클라우드 워치의 실시간 데이터와 15분 정도의 시차 발생
- 그라파나는 직접 쿼리를 사용하여 데이터를 가져오기 때문에 조회하는 동안 최신 데이터를 확인할 수 있음.
Prometheus
- 시스템으로부터 각종 모니터링 지표를 수집하여 저장하고 검색할 수 있는 시스템
- 그라파나를 통하여 시각화할 수 있다.
LOKI
- 수평적으로 확장 가능하고 가용성이 뛰어난 멀티테넌트 로그 집계 시스템
- Prometheus에서 영감을 받은 시스템
- Loki는 메트릭 대신 로그에 초점
- 풀 방식이 아닌 푸시 방식으로 로그를 수집한다는 점에서 Prometheus와 다름
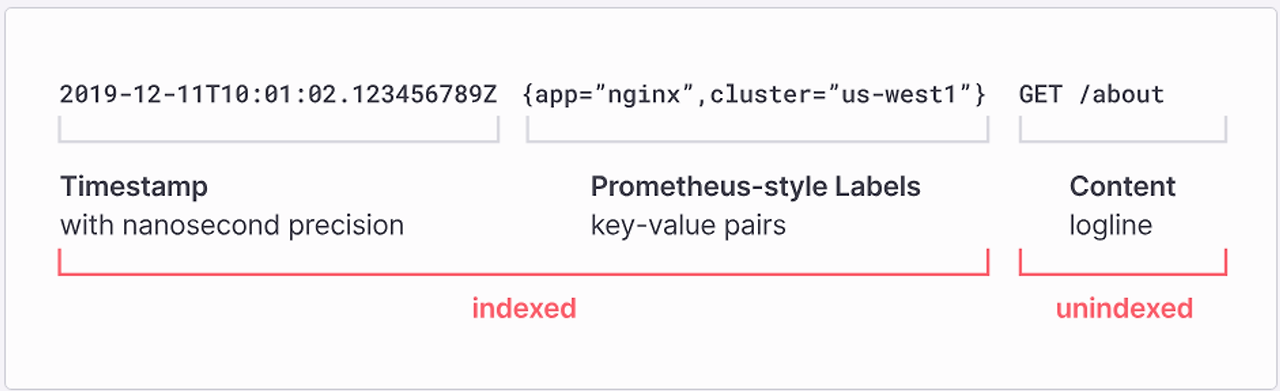
- 로그에 대한 메타데이터만 인덱싱 한다는 아이디어, 즉 레이블을 기반으로 구축.
- 로그 내용을 색인화하는 것이 아니라 각 로그 스트림에 대한 레이블 세트를 색인화하기 때문에 레이블 단위로 로그는 별도로 압축되어 청크 단위로 저장이 되고 압축률에 따라 데이터 감소
ELK Stack에서 Loki로 전환하는 사례
- Elasticsearch의 높은 비용, 대규모 클러스터 확장의 어려움이 발생.
- 부하가 발생하면 비정기적으로 전체 클러스터에 대한 API 접근이 실패하여 로그 전송이 되지 않는 경우가 발생
- 기존의 ELK Stack을 사용했던 과거에 비해 로그 수집량이 1.6배로 늘었지만 비용은 오히려 과거보다 약 23% 절감
따끈따끈한 전사 로그 시스템 전환기: ELK Stack에서 Loki로 전환한 이유 | 우아한형제들 기술블로그
따끈따끈한 전사 로그 시스템 전환기: ELK Stack에서 Loki로 전환한 이유 | 우아한형제들 기술블로그
안녕하세요. 클라우드모니터링플랫폼팀의 이연수입니다. 우아한형제들의 모니터링시스템 구축 및 관리, 운영을 하고 있습니다. 작년부터 올해 초까지 팀에서 전사 로그 시스템을 전환을 진행
techblog.woowahan.com
MIMIR
- Grafana Mimir는 Prometheus에 대한 확장 가능한 롱텀 스토리지를 제공하는 오픈 소스 프로젝트
- 확장성, 쉬운 설치 및 관리, 비용 효율적인 스토리지 솔루션
- TSDB를 더욱 가용성 있고 확장성 있는 아키텍처로 사용 가능
- 수평적 확장이 가능하고, 장기간 보관할 수 있는 Object Storage에 Metric을 보관하는 이점이 있다.
Tempo
- Grafana Tempo는 사용하기 쉬운 오픈 소스 기반의 대규모 분산 추적(Trace) 백엔드
- Tempo를 사용하면 추적을 검색하고, 스팬에서 메트릭을 생성하고, 추적 데이터를 로그 및 메트릭과 연결할 수 있다.
Trace란?
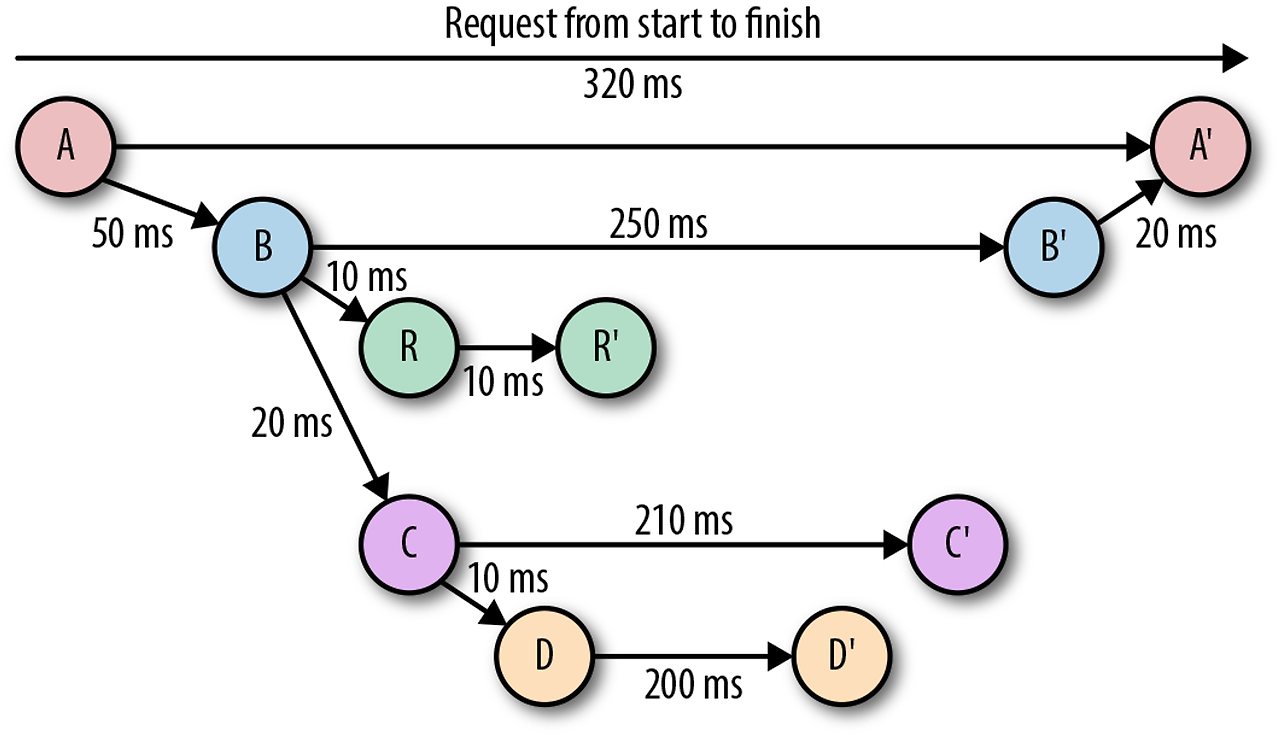
- 분산되어 있는 이벤트 간의 연관성을 하나의 플로우로 표현하는 관측 가능성 요소
- 서비스 요청의 레이턴시가 증가했을 때, 원인을 파악하기 위해 트레이스를 사용
- 트레이스는 각 요청마다 고유한 ID를 부여한다.
- ID를 가진 요청이 이벤트를 발생시킬 때마다 이벤트의 시작시간과 끝시간을 측정해 레이턴시를 파악한다.
- 고유한 ID를 가진 이벤트끼리 묶어주면 다이어그램이 완성된다.
예제
Prometheus (프로메테우스) 대해 알아보고 설치해보자
Prometheus (프로메테우스) 대해 알아보고 설치해보자
Prometheus (프로메테우스란)? 지표들을 시계열 데이터로 수집하고 측정하는 오픈 소스 모니터링 툴킷을 말한다. 여기서 지표라는 것은 예를 들어 웹 서버같은 경우 "요청수", "지연시간" 등이 될 수
yscho03.tistory.com
Getting Started: Monitoring a FastAPI App with Grafana and Prometheus - A Step-by-Step Guide
Getting Started: Monitoring a FastAPI App with Grafana and Prometheus - A Step-by-Step Guide
Introduction Monitoring plays a crucial role in ensuring the performance, availability,...
dev.to
Technical documentation | Grafana Labs
Technical documentation | Grafana Labs
Thank you! Your message has been received!
grafana.com
Prometheus - Monitoring system & time series database
Prometheus - Monitoring system & time series database
An open-source monitoring system with a dimensional data model, flexible query language, efficient time series database and modern alerting approach.
prometheus.io
OpenTelemetry
High-quality, ubiquitous, and portable telemetry to enable effective observability
opentelemetry.io
GitHub - open-telemetry/opentelemetry-python: OpenTelemetry Python API and SDK
GitHub - open-telemetry/opentelemetry-python: OpenTelemetry Python API and SDK
OpenTelemetry Python API and SDK . Contribute to open-telemetry/opentelemetry-python development by creating an account on GitHub.
github.com
Quick-Start to Integrating OpenTelemetry with FastAPI (Part 1)
Quick-Start to Integrating OpenTelemetry with FastAPI (Part 1)
No long useless rants here. Just code. Let’s go!! (That snack saw me through some of the code below, so it deserves a place here!)
medium.com
OpenTelemetry FastAPI Instrumentation — OpenTelemetry Python Contrib documentation
OpenTelemetry, Grafana, Loki, Tempo, Prometheus를 활용한 Flask Observability 구성하기
OpenTelemetry, Grafana, Loki, Tempo, Prometheus를 활용한 Flask Observability 구성하기
OpenTelemetry Metrics, Traces, Logs 정보를 수집하고 데이터를 Grafana Loki, Grafana Tempo, Prometheus에 저장 후에 Grafana를 통한 대시보드를 구성하는 방법에 대해서 알아보도록…
medium.com
GitHub - baiyongzhen/flask-observability
GitHub - baiyongzhen/flask-observability
Contribute to baiyongzhen/flask-observability development by creating an account on GitHub.
github.com
OpenTelemetry 란 무엇인가?
MSA기반으로 개발된 서비스가 많아지고, 서비스 간의 관계가 점점 복잡해지면서 장애 분석 및 버그 추적이 점점 어려워지고 있습니다. 서비스의 관측성(Observability) 확보를 위한 다양한 상용 서비
medium.com
Pull or Push: How to Select Monitoring Systems?
Pull or Push: How to Select Monitoring Systems?
This article introduces the Pull or Push selection in the monitoring system, comparing the two on the basis of various aspects encountered during actual customer scenarios.
www.alibabacloud.com
Grafana Loki란? 개념부터 설치까지
Grafana Loki란?Grafana Loki는 Prometheus에서 영감을 받은 로그 집계 시스템으로, 로깅 및 이벤트 데이터를 수집, 저장 및 검색하기 위한 오픈 소스 플랫폼이다. 비용 효율적으로 운영하기 쉽게 설계되었
wlsdn3004.tistory.com
트레이싱 관측 도구 Grafana Tempo로 트레이스를 관측해보자
트레이싱 관측 도구 Grafana Tempo로 트레이스를 관측해보자
우리가 관측 가능성(Observability)에 대해서 말할때, 보통 시계열의 수치 데이터를 뜻하는 메트릭(Metric)이나 인간이 읽을 수 있는(human-readable) 형태로 상태를 출력하는 로그(Log)를 떠올릴 것입니다.
nangman14.tistory.com
Opentelemetry로 Kubernetes Observability 확보하기 : Monitoring
Opentelemetry로 Kubernetes Observability 확보하기 : Monitoring
본 포스팅은 "Opentelemetry로 Kubernetes Observability 확보하기" 시리즈의 2번째 글입니다. 저번 포스팅에서 Opentelemetry를 사용해 Logging에 대한 가시성을 확보하는 방법에 대해 알아봤습니다. 이번에는 Thr
nangman14.tistory.com
https://nyyang.tistory.com/175
Grafana Monitoring 스택 LGTM 구성기 (Loki, Mimir, Tempo)
아직 LGTM(Loki , Grafana , Tempo , Mimir)관련 한글 자료가 별로 없어서 간략하게 작성해본다.회사에서 도입을 고민하고 있거나 PoC 중이라면 이 글이 조금의 도움은 될 수 있겠다고 본다. LGTM이란 무
nyyang.tistory.com
'스터디 > 사내 스터디' 카테고리의 다른 글
| 파이썬 코드 패키징과 배포 (Poetry, Venv, Pip) (0) | 2024.08.14 |
|---|---|
| 이벤트 기반 아키텍처 (Event Driven Architecture) (1) | 2024.07.10 |